
Summary:
In this talk at Gen AI Summit 2023, the speaker, Prof. Liang, emphasizes the importance of benchmarking in the field of AI, particularly for language models. He highlights the need for transparency, objective assessment, and better industry standards in benchmarking language models. The speaker introduces HELM (Holistic Evaluation of Language Models), an ongoing benchmarking effort that aims to achieve broad coverage, consider multiple metrics, and ensure standardization. He discusses the evaluation of diverse models using different scenarios and metrics, promoting transparency through rankings and individual model predictions. The speaker also invites the community to contribute to HELM and emphasizes the collaborative nature of benchmarking to track the progress of foundation models accurately.
Video:
Full Transcripts:
Alright, hello everyone. I'm really happy to be here, thanks to the organizers for having me. We are living in an era of foundation models, which is an incredibly exciting time. But I want to talk about benchmarking. So, benchmarks orient AI. If it weren't for benchmarks, if it weren't for ImageNet, what would the deep learning revolution look like in computer vision? If it weren't for SQuAD or SuperGLUE? What would a deep learning revolution look like in NLP benchmarks? They give the community a Northstar. Something to hill climb on. And over time, we see benchmark progress going up and up. But I also want to point out that benchmarking encodes values, and encodes what we as a community care about, measuring the decision of what tasks to focus on, what languages, and what domains. All of these things determine the shape that technology follows. So, the very important thing, is that's what I have as the number one takeaway for this talk. I want to impress on you how central benchmarking is. We like to think about methods, products, or demos, but none of this would be possible without the measurement that drives technology forward.

So now we are here in 2023. The slide is probably out of date because models keep coming out every month. There's just an explosion of different models, language models, by Foundation models more generally, which can include text image models. We all know about GPT-4, I don't need to tell you how amazingly impressive it is. But how do you benchmark these things? And I want to stress that this is a bit of a crisis. I think we are losing our ability to measure the quality of these models. The pace of innovation is happening so quickly that we're not able to measure it. Back in the day, If you put out a benchmark, it would last a few years because people would make progress toward it. And now, the pace of foundation models has outstripped our ability to keep up. So we need to do something about it.
Okay, language models. So everyone knows what a language model is. But here's one way to think about it. It's just a box that takes the text in and produces text. So in some sense, it's a very simple object. Right? It couldn't be even simpler. So what's so hard about this? Well, what's hard about it is that this deceptively simple object leads to a number of different applications, an infinitude of different applications. You can generate SQL, emails, revise, explain jokes, and more with just a single model. That's what the paradigm shift is about. This is why we have general-purpose foundation models that can do all these things rather than having bespoke models for every single task. But that makes benchmarking a little bit of a nightmare.

So what do we want from benchmarking language models? We want transparency. We want to understand what language models can do and what they can't do. If you go on Twitter, you can see all the amazing things, all the demos. You can also see all the people who say no, GPT-4 failed at this. And so what's the truth? Where is the objective way to think about what these models are capable of? We need to develop better industry standards. Everyone evaluates slightly different things. Which model is better? We need to standardize, and also we need to ground the conversation out. Many of you are trying to make the decision of which model to choose. And as a scientist, I believe that we need to have the facts. Once you have the facts, you can make informed decisions. And finally, benchmarking classically has served as a guide, a post for researchers. We want to use benchmarks to develop socially beneficial and reliable models. We want these benchmarks to be ecologically valid, not toy tasks, but things that show up in the real world. We want to go beyond just accuracy and measure other concerns such as bias, robustness, calibration, and efficiency. And I think we need to consider human values in the process here.

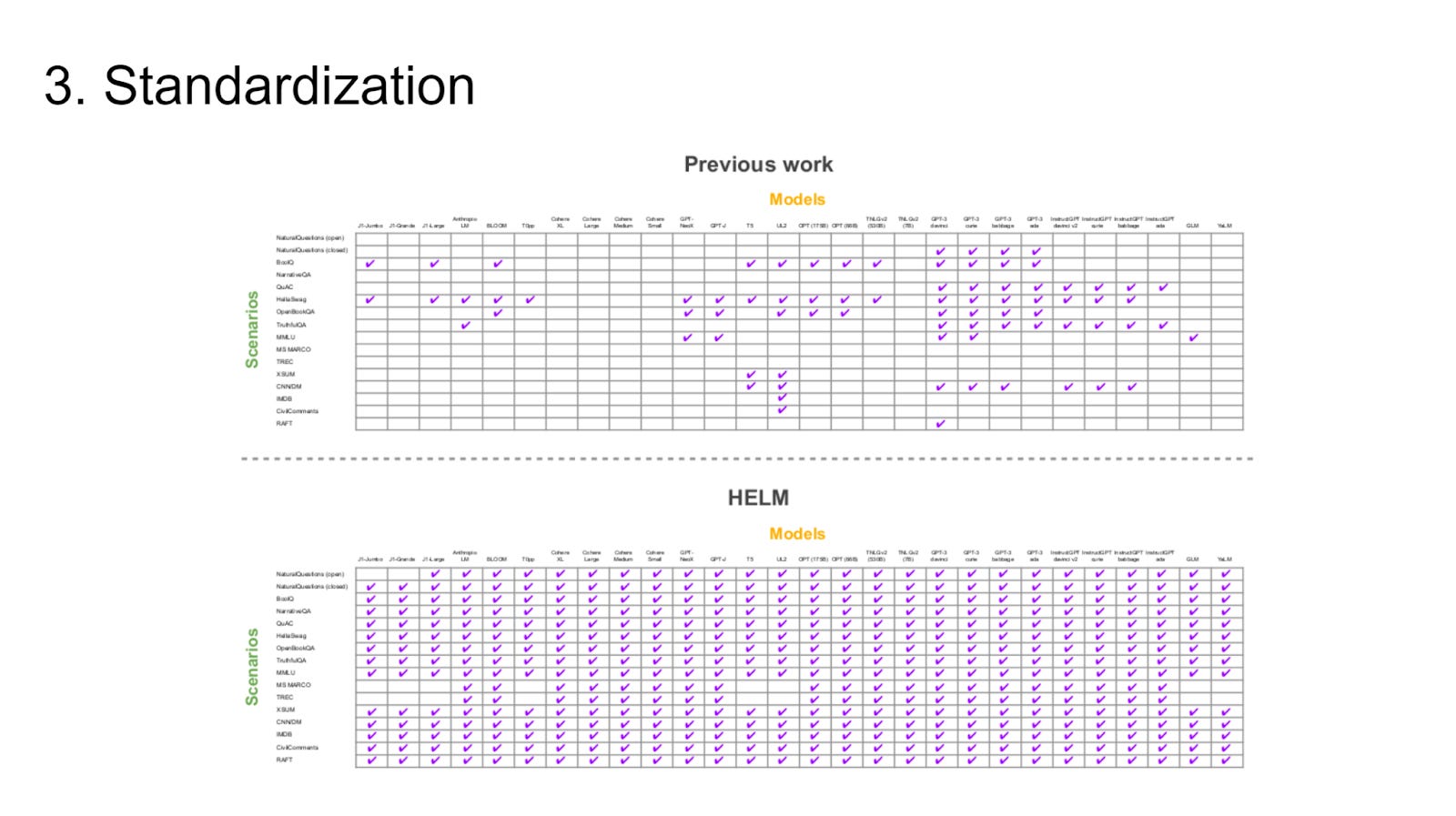
So, last year, we released the first installment of our benchmarking efforts at the Center for Research on the foundation model called HELM (Holistic Evaluation of Language Models). This is an ongoing effort, and I'm going to explain how we designed the benchmark. The first principle, among the three, focuses on the broad coverage and recognition of incompleteness. Typically, benchmarks like Big Bench or Eleuther's LLM harness consist of a list of tasks such as question answering, text classification, and language modeling. However, we questioned why these specific tasks were chosen and what might be missing. We realized the need for a more systematic approach considering the extensive capabilities of these models. In HELM, we built a taxonomy of tasks, taking into account the domains, text generators, and languages involved. We also acknowledged that many cells in the taxonomy remain empty due to a lack of support. Recognizing this incompleteness, we understand that the benchmark is an ongoing process, where we strive to measure aspirational goals within the constraints of available resources.

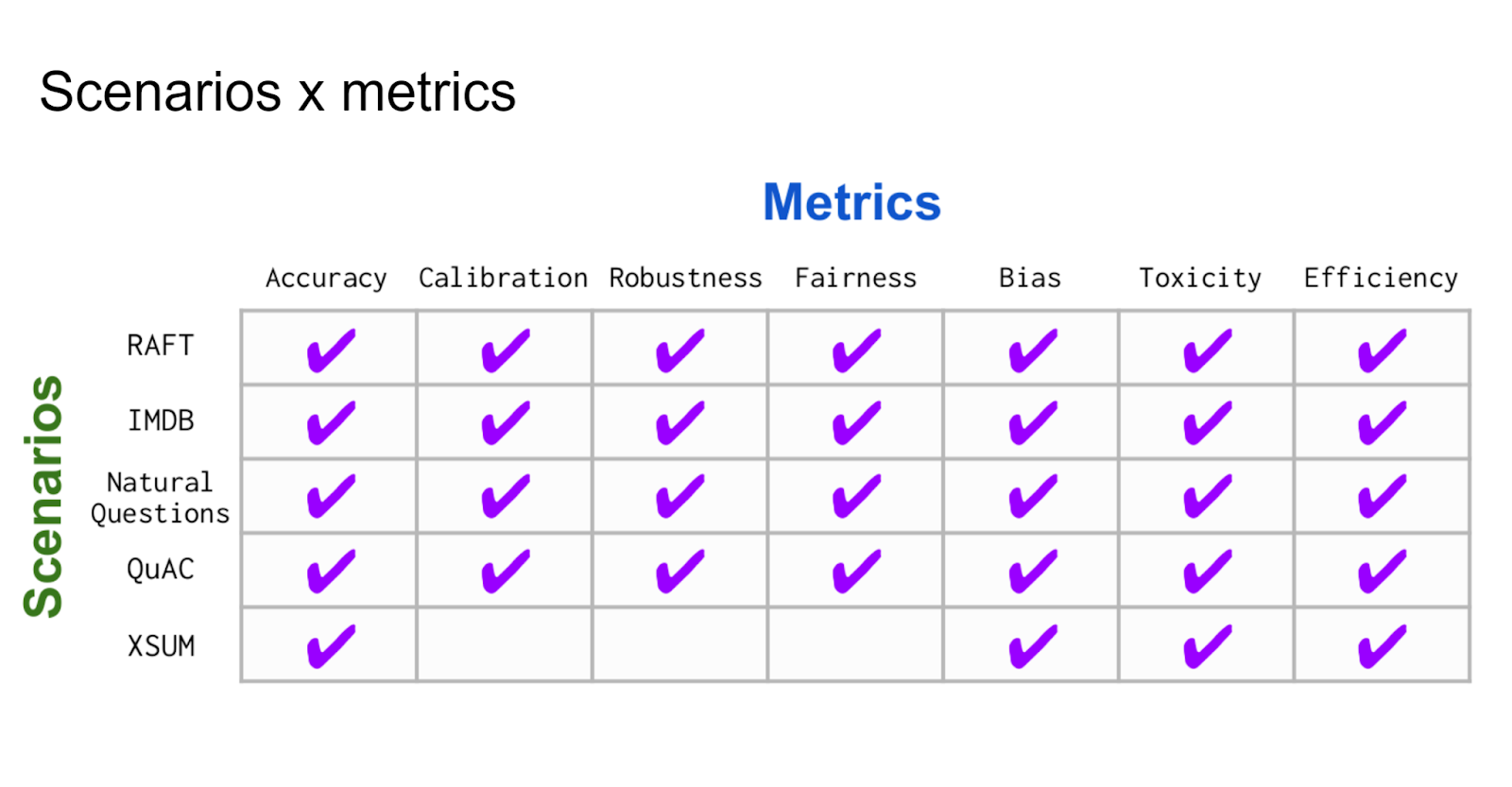
The second aspect to highlight is that benchmarks typically focus on a single metric, which is often preferred for simplicity. However, given the complexity of the world, accuracy alone is not sufficient. We aim to consider calibration, which assesses whether models are aware of what they don't know. As I will demonstrate later, these models can often be confidently wrong, which raises concerns about their robustness. If slight changes in input result in significant output variations, these models may not be robust. We also investigate fairness across diverse demographic groups, addressing biases and the generation of toxic content. Additionally, we evaluate the efficiency of the models.

Lastly, standardization is the third aspect we emphasize. Unlike the ad hoc nature of previous benchmarking approaches, HELM takes a systematic approach. We ensure that every model is compared fairly to the same set of scenarios. We cover a wide range of tasks, including question-answering, information extraction, summarization, toxicity classification, sentiment analysis, and more. Each scenario undergoes evaluation, assessing classic accuracy. For certain tasks like summarization, human evaluation becomes necessary. We caution against relying solely on metrics like rouge, as they may not correlate strongly. We also examine calibration, which measures the model's confidence in its predictions, considering the importance of uncertainty in threading these models into larger systems. Robustness is assessed by observing how models respond to changes in input, ensuring they remain invariant. We narrow our focus on fairness by examining gender and race biases. Additionally, we address the generation of toxic content, measure efficiency, and account for factors like API query time and model architecture to obtain a more accurate understanding of model efficiency.
To summarize, our benchmarking efforts in HELM center around three principles: broad coverage and recognition of incompleteness, consideration of multiple metrics beyond accuracy, and a focus on standardization. Through this approach, we strive to comprehensively evaluate language models and gain meaningful insights into their capabilities.
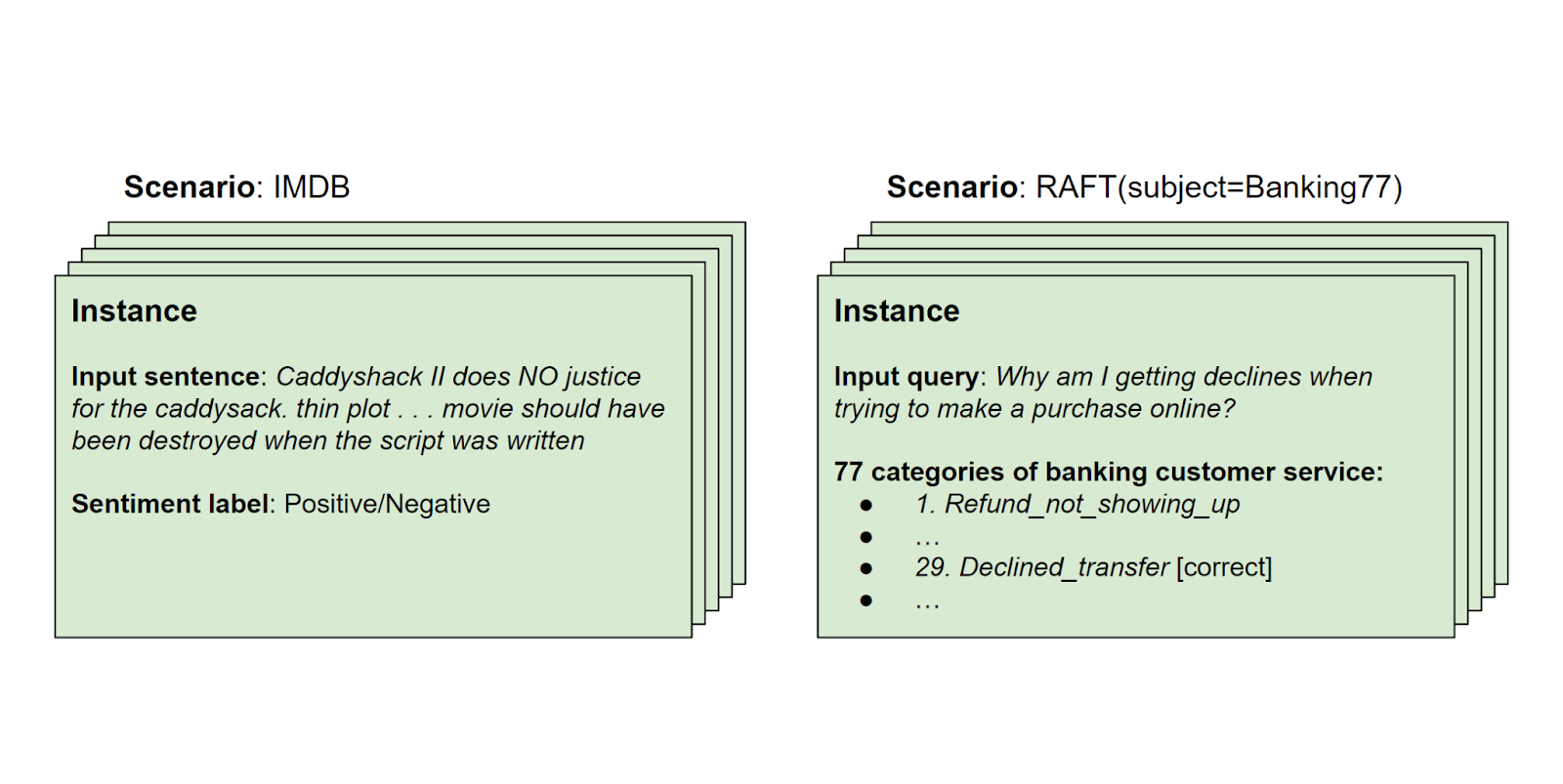
And now, let's cover all the scenarios systematically to ensure every model is compared fairly on the same grounds. So, let me provide you with an overview of the initial types of scenarios we examined. Keep in mind that this list is continually evolving, so it's not limited to these examples alone. We explored question-answering, information extraction, summarization, toxicity classification, sentiment analysis, and various other types of text classification tasks. Additionally, there are scenarios involving coding reasoning, legal datasets, medical datasets, and more.
For each scenario, we evaluate and run the model, measuring its accuracy. This assessment includes the classic accuracy aspect, determining whether the question was answered correctly or not. However, for certain tasks like summarization, human evaluation is deemed absolutely necessary. So, be cautious when reading papers that report on metrics like rouge, as they may not be strongly correlated with true performance. Furthermore, we delve into calibration, which addresses the confidence level of the model's output. For example, if the model states it's 70% certain about a certain answer, it should be correct about 70% of the time. Otherwise, the probability loses its meaning. This confidence is crucial when incorporating these models into larger systems, as we need to consider the uncertainty to avoid a fragile system. Robustness plays a role in observing how models handle changes in words, such as introducing typos or altering capitalization. Ideally, models should remain invariant to such perturbations. However, we noticed that some models exhibit changes in predictions as a result. In terms of fairness, our focus is on a narrow subset that considers gender and race. We analyze whether replacing outputs from one gender with another produces similarly high-quality results. Bias measurement involves examining how these models generate certain types of words, such as the co-occurrence of mathematicians with gendered terms. Toxicity is an aspect we're all familiar with, and it is certainly essential to address. Additionally, we prioritize efficiency, particularly when considering the real-world deployment of foundation models. Waiting for a response for 10 seconds is undesirable. However, measuring efficiency is somewhat tricky. On one hand, querying the model using an API can provide a measurement, but this depends on factors like how many resources the model provider allocates and your position in the queue. To obtain a more accurate understanding of model efficiency, we also compute an idealized runtime in cases where we have access to the model architecture, allowing us to standardize across hardware. In summary, our approach in HELM involves representing scenarios as rows, reflecting the various situations and use cases where language models are applied. The metrics, represented as columns, capture the aspects we care about and define what we want the language model to achieve.
So let's delve into the models themselves. We evaluated 30 models from various organizations such as AI21, Anthropic, Cohere, Eleuther, Big Science, Google, Meta, Microsoft, Nvidia, OpenAI, Tsinghua, and Yandex. Over time, we have added more models, including Alfalfa from Europe and several other open models that we are currently incorporating. Some of these models are closed, and we only have API access to them, while others are open, allowing us to download the model weights. For the open models, we evaluate them using the Together platform.
One important aspect to highlight about the results is our commitment to full transparency. When you visit our website, you will find not only tables that rank the models based on different criteria but also detailed information. For instance, if you come across a value like 56.9, you may wonder if it's good or bad. By double-clicking on it, you can access individual instances, where specific questions, answers, and model predictions are displayed. This enables you to judge the performance for yourself. This level of transparency is particularly crucial for generative cases, where model outputs are rated, such as receiving a rating of 4.5. It's essential to be skeptical of such metrics since these complex systems make measuring quality an imperfect process. Therefore, we provide the runs and generations for people to assess. The code is open source, publicly available, and it's a community project. Contributions of scenarios, metrics, and models are welcome, making this an ongoing collaborative effort. We have been updating it monthly since its launch in December, and we are continually adding new models, including GPT-4 in the near future, as well as incorporating additional open models.
Now, let's shift gears and discuss related projects within the evaluation theme that we have been exploring. While HELM initially focused on language models, we recognize the need to consider foundation models more broadly, including multimodal models capable of processing both images and text. The interface would involve not just text inputs, but also sequences of text and images, producing not only text but also text and images as outputs. We are beginning with text-to-image models like DALL·E and Stable Diffusion, and we aim to maintain a systematic approach in evaluating these models across various aspects, such as quality, originality, knowledge representation, bias detection, toxicity, and more.

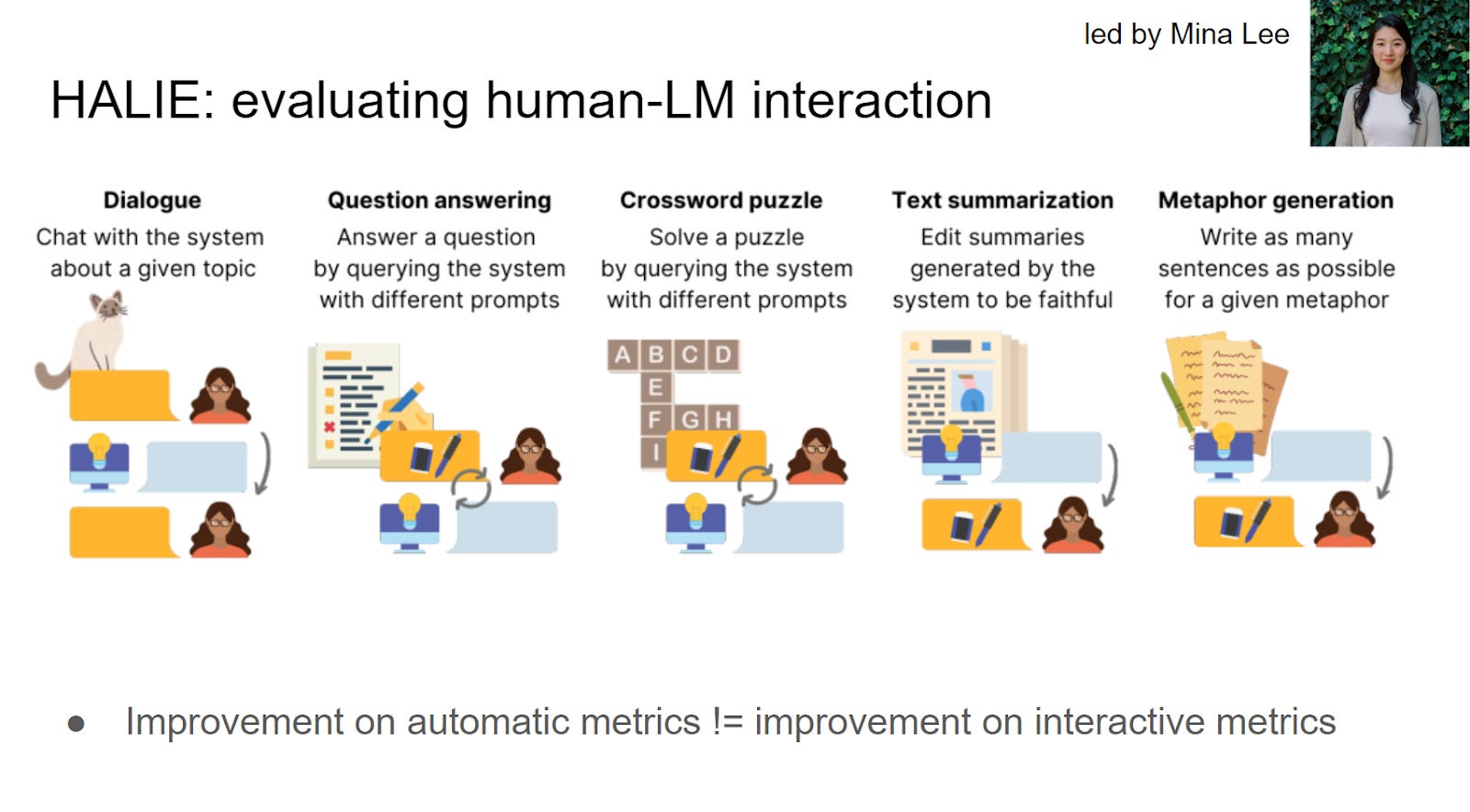
Another point to mention is the use of many of these models in a human-in-the-loop context. For instance, when using ChatGPT, the interaction is not limited to a single input; it involves an ongoing dialogue. Currently, our ability to measure interactivity is limited, and there is a need to evaluate not just the language model itself but also the interaction between humans and language models. Considering the human-LM interaction as a unified system is crucial. We have observed that, in many cases, the top-performing models, like OpenAI's Text-Adventure-03, excel, but not always. There are instances where improvements based on automatic metrics do not necessarily translate into improvements in interactive metrics. Sometimes, an automatic metric may lead the model to generate outputs that are locally optimal but challenging for humans to work with. Thus, thinking in terms of human interaction is an important next step, especially as these models are deployed to interact with humans.
A related project here focuses on the verifiability of generative search engines, such as Bing Chat and Neva Perplexity. These search engines provide answers not only through search results but also by generating text with citations. At first glance, the presence of citations might lead us to trust the answers. However, upon closer examination, we found that only 74% of the citations actually support the statements. This is embarrassingly low, highlighting that the mere presence of a citation does not guarantee the faithfulness of the generated text. This ongoing effort prompts us to consider adding Bard to the list of evaluations. An interesting aspect of this project is the trade-off between perceived utility and the accuracy of citations. It's important to note that I mentioned perceived utility. Some models generate helpful and fluent texts that sound reliable but are entirely fabricated. On the other hand, big chat generally generates faithful content by directly copying and pasting from sources. However, it may be perceived as less useful due to the lack of creativity. This trade-off emphasizes the need for rigorous benchmarking to uncover such nuances and make meaningful progress.

To conclude, I want to emphasize the significance of benchmarks in the field of AI. They provide direction and determine the trajectory of our community. Language models present unique challenges compared to simpler tasks like dog versus cat classification, which are relatively straightforward to benchmark. Language models are versatile and capable of performing various tasks. Therefore, HELM, our holistic evaluation effort, aims to tackle this ambitious task by considering a wide range of scenarios and evaluating multiple metrics beyond just accuracy. It's crucial to emphasize that we cannot accomplish this alone; it requires a collaborative community effort. If any of you have interesting use cases from domains like law, medicine, finance, coding, or poetry generation, please contribute. Once we have a critical mass of scenarios, we can collectively define our goals, measure progress, and provide a useful and up-to-date resource in the form of a dashboard. The lighthouse image serves as a symbol of what HELM represents—illuminating the rapidly evolving field of foundation models. Thank you for your attention.

Call to Action
AI enthusiasts, entrepreneurs, and founders are encouraged to get involved in future discussions by reaching out to Fellows Fund at ai@fellows.fund. Whether you want to attend our conversations or engage in AI startups and investments, don't hesitate to connect with us. We look forward to hearing from you and exploring the exciting world of AI together.








