
Haixun Wang, VP of Engineering at Instacart, Distinguished Fellow at Fellows Fund, IEEE Fellow
Part III of Embracing Generative AI: The Dawn of a New E-commerce Experience

Who will lead the e-commerce revolution in the age of generative AI? Will it be established tech firms like Google, Microsoft, and OpenAI, expanding their general-purpose platforms into e-commerce, or niche players using generative AI to create mountains of content in their corner of the market? Alternatively, will established e-commerce companies triumph by integrating generative AI to boost every step of their operation, from search, discovery, to delivery?
This section charts a course for established e-commerce companies in the early days of generative AI. While the temptation to rapidly adopt every new innovation from OpenAI or DeepMind is strong, lasting success will likely come from leveraging generative AI to bolster their existing strengths, which lie in their proprietary data, including catalog/inventory, user engagement, etc. Generative AI can refine and enrich this data, and by generating new content and insights, it can help create a formidable moat, solidifying their competitive edge in an evolving market.
This roadmap suggests three primary focus areas:
- Data and Knowledge Management: Enrich the data and unleash its power.
- Personalization: Use AI to craft experiences tailored to each user’s preference.
- Infrastructure for Generative AI: Build the technological backbone to support AI integration.
While generative AI unlocks dazzling possibilities like AR/VR and hyper-personalized shopping, the focus of this section is not such applications. Rather, the goal is to lay a solid foundation, ensuring e-commerce platforms make the most of their AI investment and stay ahead in the AI revolution.
Data and Knowledge
As we shift towards AI-powered e-commerce, placing a high priority on data becomes a strategic imperative for a multitude of reasons.
First, e-commerce is fundamentally data-driven, where critical datasets like catalog data, user engagement data, and product knowledge graphs play a vital role. However, difficulties in utilizing this data have contributed to a long-standing stagnation in the improvement of the e-commerce experience.
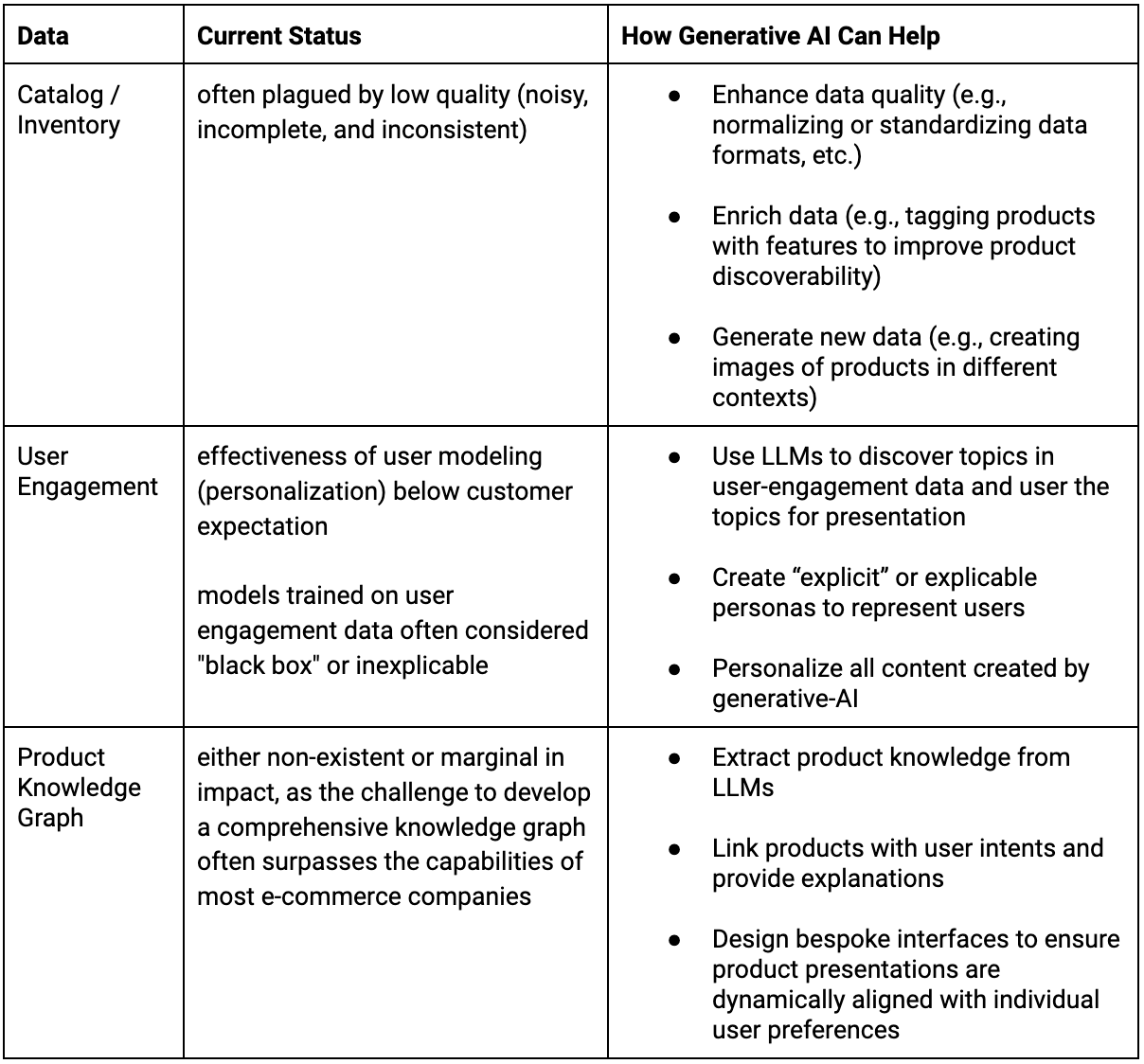
Second, LLMs possess a wealth of knowledge, encompassing not just intricate product details but also their practical uses in various scenarios and alignment with diverse user intents. This opens up a wide range of possibilities for e-commerce. LLMs can significantly enhance the system’s ability to understand customer queries, effectively bridging the divide between customer needs and appropriate products. Additionally, they are capable of creating adaptive interfaces, ensuring optimal product presentation tailored to different settings and preferences. Fig. 13 summarizes the pivotal role of generative AI in data enhancement and content creation.
Third, currently, the reliability of LLMs is often compromised by issues such as ‘hallucinations,’ making the development of dependable real-time applications a challenge. However, with the rapid advancement of LLM technologies, this landscape could soon shift. Thus, it may be prudent to shift focus away from ambitious real-time applications towards data-centric initiatives for two key reasons. First, these initiatives may prove more cost-effective, as the challenges of reliability can be more effectively managed with robust quality control processes in a non-real-time setting. Second, such investments are likely to yield lasting, valuable data and knowledge assets, which help reinforce an e-commerce company’s competitive edge.
In the following, we give a few examples of how LLMs and generative AI can help in the realm of data.
Enriching catalog data
With generative AI, we may significantly enhance the quality of catalog data. Here is an example of using LLM to tag products with specific features.
In a typical catalog, a product is listed with a name and description. For example:
Product name:
Swiffer Antibacterial Cleaner, Febreze Citrus & Light Scent, Refill
Product description:
Kills 99.9% of bacteria (Kills 99.9% of staphylococcus aureus and enterobacter aerogenes). Helps eliminate odors in the air with a fresh scent. Great for vinyl, glazed ceramic, sealed marble, laminate, and finished wood floors. Do not use on unfinished, oiled, or waxed wooden boards, non-sealed tiles, or carpeted floors because they may be water sensitive. Good Housekeeping: Since 1909. Limited warranty to consumers. Replacement or refund if defective. Contains no phosphate, chlorine bleach or ammonia. Questions? 1–800–742–9220. www.swiffer.com. Bottle fits all Swiffer Wet Jet devices.
By utilizing an LLM, we can extract and tag key attributes from this information, improving the product’s visibility in search results and its alignment with user needs. The LLM might generate output like this:
Output:
{
"Antibacterial": true,
"Scent": "Febreze Citrus & Light",
"Suitable Floor Types": ["Vinyl", "Glazed Ceramic", "Sealed Marble", "Laminate", "Finished Wood"],
"Not Suitable Floor Types": ["Unfinished, Oiled, or Waxed Wooden Boards", "Non-Sealed Tiles", "Carpeted Floors"],
"Phosphate Free": true,
"Chlorine Bleach Free": true,
"Ammonia Free": true,
"Brand": "Swiffer",
"Compatibility": ["Fits all Swiffer Wet Jet devices"],
"Product Type": "Floor Cleaner",
"Package Type": "Refill"
}
This detailed and structured output not only aids in better product discovery but also ensures a more precise match with customer queries and preferences.
Product attribute tagging is likely the most direct application of generative AI in catalog management. Generative AI can also be used to expand the catalog. For instance, a grocery e-commerce company like Instacart may adopt a culinary content strategy to generate tailored recipes. If a customer shows interest in salmon, AI could provide various recipes featuring salmon. Additionally, AI can craft recipes from a customer’s available ingredients, like creating a creamy chicken and broccoli pasta recipe given that the customer has chicken breast, broccoli, and pasta in his shopping cart.
Another important area where generative AI can help is in product imagery, where text-to-image models can be used to craft appealing visuals for both current and “AI-created” products, providing an efficient and scalable solution for enhancing e-commerce presentation.

Fig. 14 demonstrates that AI-generated imagery could significantly enhance the visual appeal of product presentations for e-commerce platforms. Fig. 14 (a) illustrates the transformation of a toaster’s presentation. The original image, which features the toaster against a blank, nondescript background, is stark and uninviting. Generative AI skillfully inserts the toaster into a seasonal setting, complete with warm tones and an inviting breakfast scene, making it more appealing to potential customers. This not only draws the customer’s eye but also contextualizes the product in a real-life scenario, which can be a powerful marketing tool for the brand. Fig. 14 (b) shows an artistic depiction of an apple. The lighting and shadow play gives it a more premium look. Fig. 14 (c) presents a copper mug placed in an engaging setting with ingredients around it, suggesting use and authenticity.
In addition to generating images for existing catalog items, generative AI models can also produce visuals for conceptual “AI-created” products.
For example, generative AI models can design composite visuals that coherently feature multiple products within a single, cohesive setting, complete with backgrounds and appropriate staging (For instance, an AI could generate an image that artfully arranges a set of kitchenware on a rustic table to evoke a homey cooking atmosphere, thereby appealing to the emotions and aesthetic preferences of potential customers.)

Another application is the creation of images for AI generated recipes. Fig. 15 give some examples. Moreover, Fig. 16 showcases a series of AI generated images compiled into a dynamic GIF, depicting the preparation of the dish “Raw Salmon Fillets with Herbs and Spices,” following an AI-created recipe.
It’s not difficult to imagine that AI-generated videos could have significant implications for e-commerce. It may create realistic, engaging videos demonstrating products in use, which could be more appealing and informative than static images or text descriptions.

However, maintaining the realistic and aesthetic quality of AI-generated images and videos remains a formidable task. At present, aside from human evaluation, there are no reliable ways to ensure a high level of quality.
Creating a knowledge base
For e-commerce companies, it’s crucial to connect user interests to relevant products, a task that requires specialized knowledge often absent from product catalogs. For example, it is valuable to know that certain essential oils or an epsom salt bath can help with insomnia. Furthermore, it’s important to explain why specific products are suitable for particular needs. Without such clarifications, product suggestions could appear random and unhelpful, thereby complicating the decision-making process for customers.
For years, e-commerce businesses of all sizes have made efforts to construct product knowledge graphs. The conventional approaches typically rely on extracting information from the Internet and a range of other data sources. However, because of the vast and complex nature of the relevant knowledge, these methods usually have limited or partial success.
LLMs possess a vast reservoir of knowledge, making them adept at aligning products with user needs. For example, as shown in Fig. 17, ChatGPT can identify essential oils that may alleviate insomnia, and give details about their benefits.

However, e-commerce platforms need a materialized knowledge base tailored to their products and users, rather than relying on accessing the knowledge through an online QA interface that can be latency-prone and costly.
Therefore, it’s essential to extract or distill relevant knowledge from LLMs into a knowledge base for efficient, low-latency use in the future. This process also allows for thorough quality control to mitigate potential hallucinations from LLMs. Compared with constructing a knowledge graph from varied sources, each of which requires specialized information extraction algorithms, the advantage of acquiring knowledge from LLMs lies in their unified interface: natural language.
Presentation
As discussed, the presentation of products — the way products are organized and displayed to customers — plays a crucial role in enhancing their shopping experience.
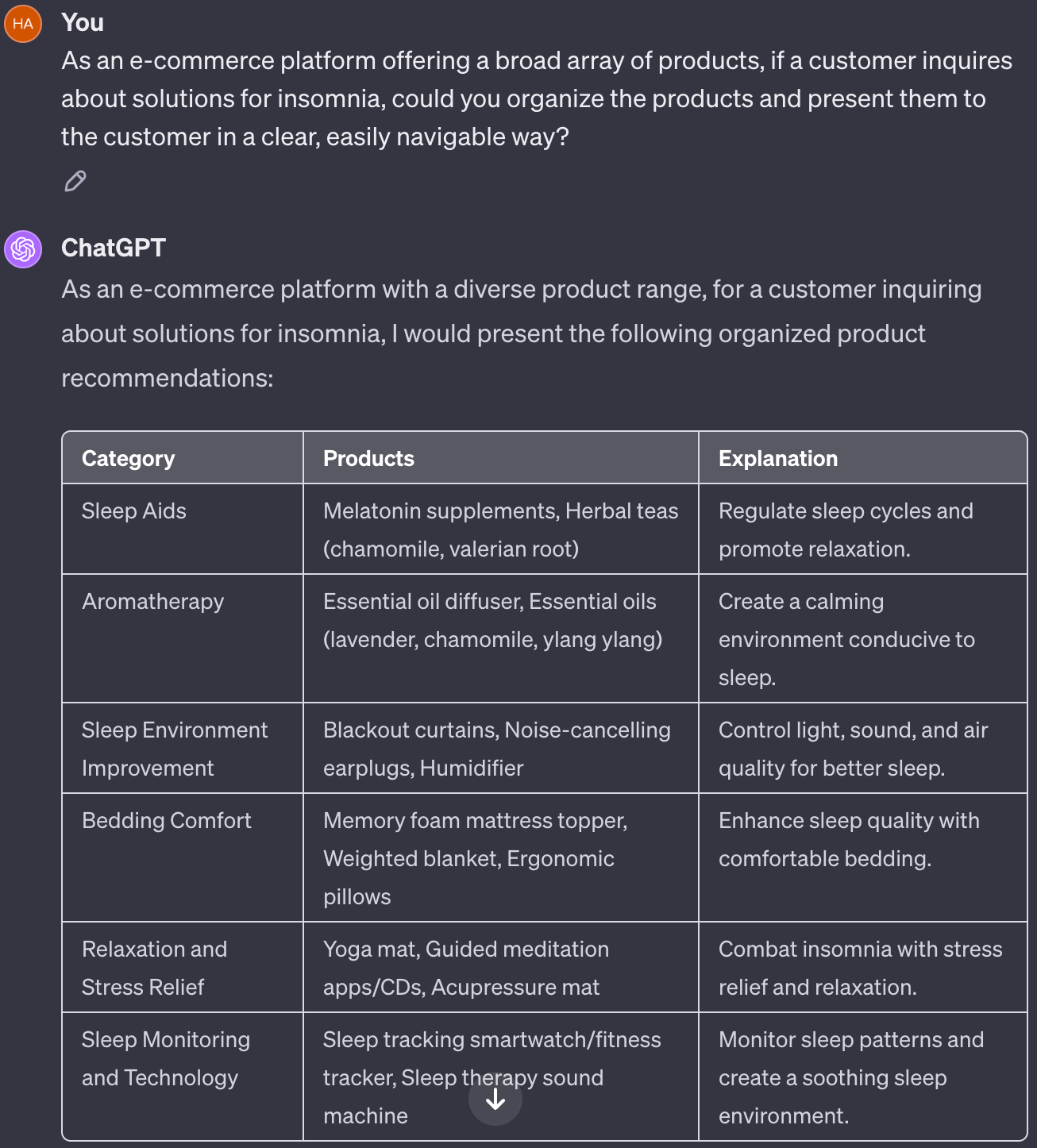
It’s vital to adjust the presentations to match the user’s search intent and context. For example, for queries about a specific product, displaying the product and related or complementary items proves effective. In contrast, for broad or vague intents such as, “Christmas gifts” or “insomnia,” offering a diverse range of options provides various perspectives, aiding customers in thoroughly exploring and assessing their choices.
The strategy of organizing products into various themes and crafting the most effective presentation for each user intent constitutes a unique form of knowledge. In Fig. 7, we introduced Google’s Gemini and its ability to create bespoke interfaces for specific user intents. Such knowledge can be effectively sourced from LLMs. Fig. 18 demonstrates ChatGPT’s knowledge in organizing the results for queries such as “insomnia” into different themes. Acquiring such knowledge from LLMs will enable us to provide a much more engaging customer experience. Furthermore, as we will show later, we can incorporate user profiles into this process to help create personalized presentations for each user.
Instead of solely relying on LLMs to categorize products into various themes, we can combine signals from user-engagement data with the knowledge in LLMs to create more relevant and engaging presentations. For example, assume user-engagement data indicates that, following the search for x, users frequently engage with products y₁, …, yₙ . We send y₁, …, yₙ to LLMs and ask the LLMs to organize them into themes. For x = “Mozzarella Shredded Cheese,” one of the themes LLMs discover from y₁, …, yₙ might be “Italian Seasoning and Spice” or “Pizza Making Supplies.” This enables us to present search results for x in coherent, theme-based groupings, instead of in a random, inexplicable manner.
Explainability
Earlier, we stressed the importance of providing explanations when aligning products with user intent. In the following, we will use advertisements as a case study to illustrate the necessity of having appropriate knowledge for these explanations.
There’s a common complaint about e-commerce systems showing too many irrelevant ads. Increasing the quantity of ads while compromising their relevance is, to put it mildly, short-sighted. It not only detracts from the customer experience but also risks increasing customer turnover.
However, at least in certain scenarios, relevance can be more about perception. If a customer gets a compelling and personalized explanation for a recommended product, what initially seems irrelevant could transform into a thoughtful suggestion. A classic example is suggesting beers to a customer looking for instant pizza delivery, particular on the day of the Super Bowl.
The key question is how to craft explanations that make a product (for example, an ad) more relevant to a user’s query. Creating these connections in advertising traditionally demands extensive manual work. LLMs could offer a promising solution to ease this labor-intensive process.
For example, when prompted to relate a bottle of orange juice to a user interested in pizza, ChatGPT offers this creative recommendation:
“Craving a pizza? How about adding a refreshing twist? Pair your favorite pizza with our zesty orange juice! Orange juice offers a delightful contrast to the savory flavors of pizza, enhancing your meal experience. Perfect for a balanced and enjoyable dining moment. Try it now with your pizza order!”
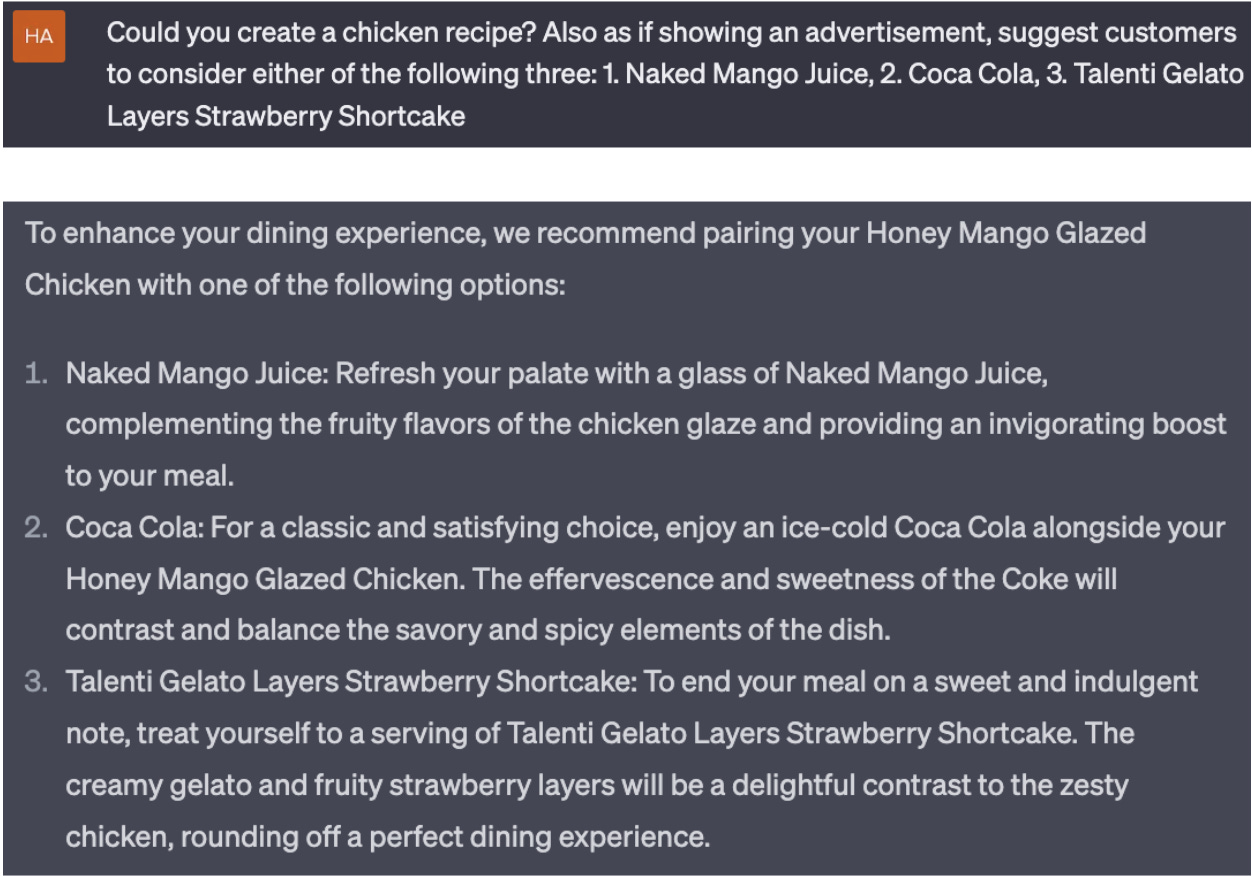
Our stress test on ChatGPT, connecting a chicken recipe to unusual picks (Fig. 19), showcases the model’s capacity for creative, yet plausible, recommendations under restrictions. Though this example provided sound results, there is a continued need for vigilance against potentially fabricated suggestions, as misleading recommendations erode trust and damage the user experience.
The possibilities of leveraging knowledge from LLMs extend far beyond what we discussed above. For example, for every product in the catalog, we may leverage LLMs to suggest complementary products, or replacement products (when it is out of stock). LLMs can suggest the perfect alcoholic pairings for any dish, recipe, or cuisine, elevating the mealtime experience. LLMs can curate unique purchases tailor-made for occasions from graduations to the big game. In all these scenarios, LLMs don’t just provide suggestions, they enrich them with meaningful explanations, building trust and enhancing the customer journey.
A takeaway strategy is to leverage LLMs to create valuable, enduring knowledge assets that can be used in many scenarios in e-commerce. In other words, it’s not necessarily about using ChatGPT as a shopping assistant in a real-time conversation. Rather, it’s about “distilling” relevant knowledge from LLMs to create a foundation of knowledge for the e-commerce business.
Personalization
Personalization is the cornerstone of success in online business. Tailoring products, services, and user experiences to individual preferences holds the key to enhancing customer satisfaction and loyalty.
So far, we have focused on how to respond to user intent (query/question) with the most relevant products and the most effective explanations, all presented in an easily understandable manner. But in essence, we want to learn the following mapping:
(query/question, user, context) => (products, explanations, presentation)
It is crucial to recognize that all interactions with users need to take into account both the user parameter (habitual user preferences) and the context parameter (situational user preferences indicated by user actions in the current session, along with broader contexts like seasons, events, etc.).
Despite significant investments by companies in sectors ranging from social networking to e-commerce to understand their customers, the results of these efforts frequently fall short of expectations. This issue is reflected in recent articles critiquing the superficial depth of personalization in online businesses. For instance, Nancy Walecki’s piece in The Atlantic, “Spotify Doesn’t Know Who You Are,” and Elle Hunt’s article in The Guardian, “Spotify knows how many hours I spent listening to Taylor Swift. But only I know why,” both underscore this point.
A key problem is that the data tracked by online businesses, like browsing habits, clicks, and purchases, are not comprehensive enough to fully understand their customers. Particularly challenging to capture are the emotions and contexts that exist beyond the scope of an e-commerce platform. We’ve discussed how generative AI, especially through multimodal models, might eventually communicate with users across all sensory channels, including text, image, vision, touch– and even, one day, the potential for AI to analyze a user’s lifelog to better understand customer needs. However, these advancements remain largely in the future.
How can we use LLMs to help improve personalization for an e-commerce platform more immediately? We will answer this question by taking a look at how personalization is handled in e-commerce business.
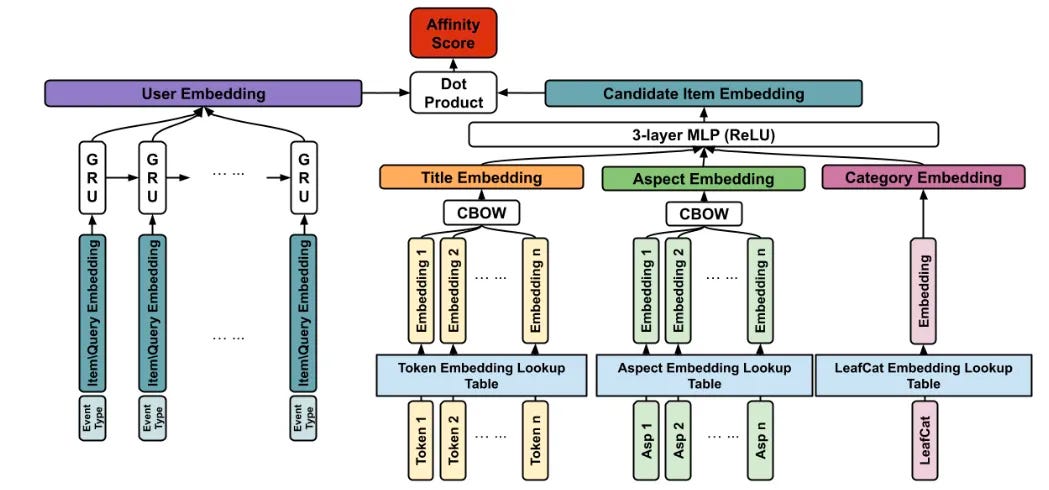
The state-of-the-art method in personalization converts personal data (e.g., browsing habits, clicks, and purchases) tracked by businesses into an implicit and inexplicable format called embeddings. These are then matched with product embeddings. For instance, Fig. 20 illustrates a deep learning architecture used for personalization, known as the two-towers model. This model consists of one tower representing users and another for products, which converge at the top for affinity calculation.
The limitation of this model lies in the difficulty to integrate additional, explicit knowledge and reasoning into personalization. The knowledge we are concerned with could range from general knowledge in LLMs (for instance, not recommending a high-sugar, high-calorie dessert like “Molten Chocolate Lava Cake” to a health enthusiast) to specific user-provided details (such as “I’m three months pregnant”). Instead, the system relies completely on inferring such knowledge from user behavior, which can be quite challenging (for example, deducing that a customer is three months pregnant from their actions alone). This issue is highlighted in Nancy Walecki’s article in The Atlantic, where she notes, “The central premise uniting these theories is that we can’t really tell an algorithm who we are; we have to show it.”
To leverage knowledge from LLMs or directly from users in personalization, one strategy involves incorporating an additional “explicit” representation of customer preferences, facilitated by LLMs. This explicit representation takes the form of natural language, which is understandable by both humans and LLMs. We achieve this by first creating a set of personas, such as the Bargain Hunter, Brand Loyalist, Impulse Buyer, Health Enthusiast, Luxury Lover, Tech Savvy, and Busy Parent, among others. We then employ LLMs to map each user to one or more of these predefined personas based on the data we have about the user. For instance, as depicted in Fig. 21, LLMs categorize a user as a Breakfast Lover based on their historical purchasing patterns.
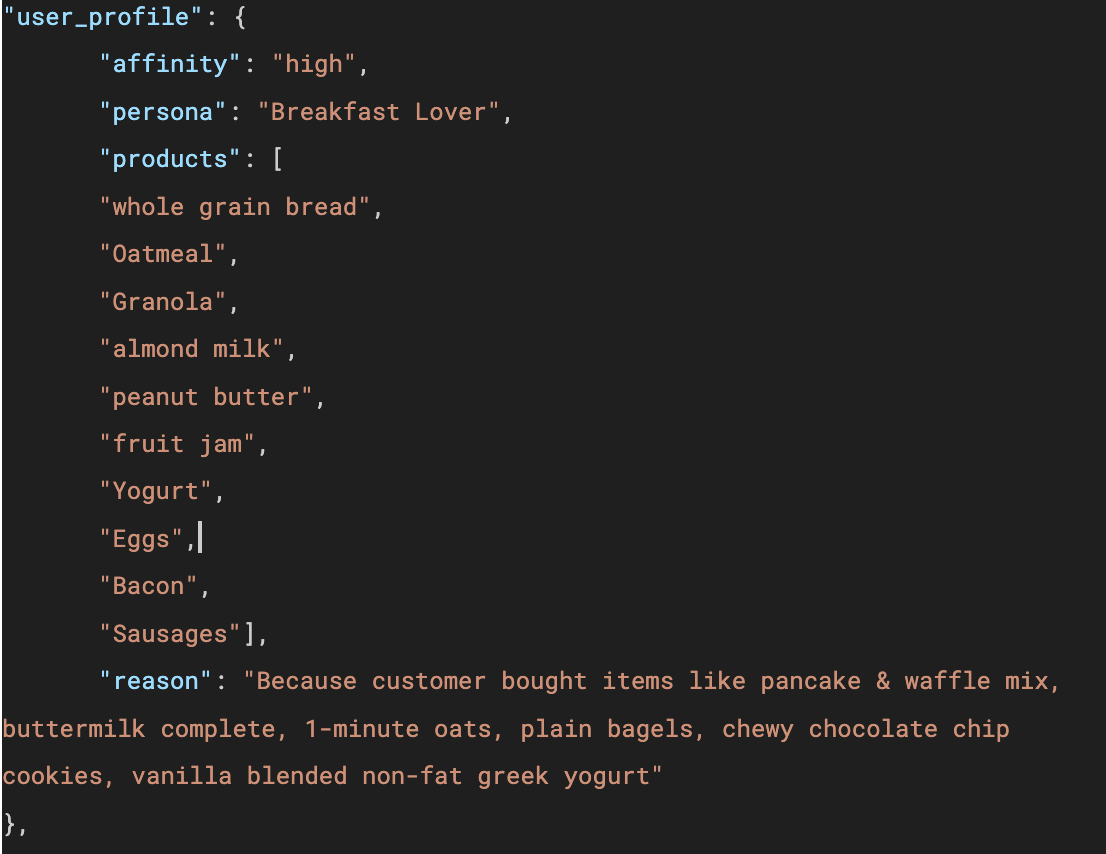
The advantage of this approach is that personas like Bargain Hunter, Health Enthusiast, and Luxury Lover are comprehensible to LLMs. Consequently, we can utilize the knowledge and reasoning capabilities of LLMs to accurately determine the appropriate selection of products, explanations, and presentations in the following effort:
(query/question, user, context) => (products, explanations, presentation)
For instance, if a user is identified as a Health Enthusiast, LLMs can focus on organic products, provide health-oriented suggestions, and arrange the product display around health-related themes.
Explicit representations are not new. In the past, e-commerce systems used surveys to gather explicit user preferences, but this method often proved to be time-consuming, not easily repeatable, and resulted in incomplete data. The integration of LLMs in explicit approaches has rejuvenated this user communication technique, adding a level of automation. The system can now proactively ask users about their product preferences, or users can directly express their likes and dislikes. This information is seamlessly integrated into their profiles and immediately influences the system’s response (in terms of products, explanations, and presentations) to user intent.
Generative AI Infrastructure
ML infrastructure plays a pivotal role in e-commerce, particularly by facilitating the deployment of a multitude of machine learning models that are critical for search, advertising, personalization, etc. It also enables the use of specialized tools like contextual bandits, enhancing various aspects of the user experience.
Many e-commerce companies still operate with ad-hoc ML infrastructures, and will require a strategic ML infrastructure upgrade for scalability and adaptability. Beyond meeting standard ML needs, the infrastructure must support generative AI driven tasks, from batch content creation to real-time chatbot interactions. Balancing these diverse needs while staying abreast of evolving services like those offered by OpenAI is key to maintaining a competitive edge in the age of generative AI.
Goals
Leveraging LLMs in e-commerce presents several challenges:
- Reliability: Ensuring reliable product recommendations to customers is crucial. LLMs’ tendency of hallucinations is a significant issue. To counter this, we need to establish advanced evaluation mechanisms, with humans in the loop.
- Evolvability: LLMs are not easily “portable” — techniques such as prompt engineering that are effective for one model (e.g., ChatGPT) may not work well for others (e.g., Gemini or Claude). Ensuring our applications can adapt to evolving LLM foundations is a key challenge.
- Customizability: Tailoring LLMs for e-commerce is complex. E-commerce has unique data (like product catalogs and ad databases) and specific business goals (like revenue and customer satisfaction). Developing LLMs that cater to these specific needs is vital.
- Scalability: Implementing LLMs in real-time can lead to latency issues, while offline usage across extensive data sets raises throughput and cost concerns. A potential solution is using smaller (e.g., 1B — 10B) LLMs to reduce costs.
E-commerce companies with limited resources face a buy vs build vs wait decision when it comes to implementing LLM solutions. Numerous providers offer tools for LLM evaluation, fine-tuning, and hosting. For instance, here are some companies specialized in LLM evaluation. Additionally, the emergence of smaller, open-source LLMs, forecasted to soon rival the performance of larger models like GPT-4, indicates that waiting for improved solutions could be a sensible decision too. However, certain tasks still require direct attention from e-commerce companies, such as enhancing scalability and developing customized enterprise LLMs tailored to their specific needs. We will delve into these particular tasks in the following sections.
Search infra in the age of generative AI
Although search infrastructure is not inherently a part of generative AI infrastructure, the rise of neural information retrieval and LLMs has greatly influenced modern search infrastructure design. It is worthwhile for e-commerce companies to delve into and understand these developments.
Today, e-commerce search still relies heavily on term-based retrieval. It requires users to convey their intentions in a few keywords. While it is a cognitive burden, it is also a practice ingrained over decades to the point where it seems more intuitive than natural language search.
Neural information retrieval or the use of embeddings to represent products addresses the “recall” issue of the classical term-based retrieval method. The rise of vector databases further accelerated the adoption of embedding based retrieval (EBR) for search. The cutting-edge e-commerce search infrastructure now integrates term-based retrieval with EBR, creating a hybrid system.
However, the key question is: what information about the query and the product is needed to make their representations more comprehensive and effective, and what kind of infrastructure support is required for this?
To tackle this challenge, I propose two architectures for search. The first one, which is shown in Fig. 22, is based on the Retrieval Augmented Generation (RAG) mechanism. It utilizes LLMs with a broad spectrum of e-commerce data to create more comprehensive representations of queries and products. The second architecture, which extends the model-based approach, directly trains an LLM with the e-commerce data. This strategy contrasts with the first architecture, where data is accessed from external storage during runtime.
The RAG-based architecture
Fig. 22 focuses on the embedding based retrieval component of the search architecture. The full architecture is a hybrid system that supports both feature-based search (e.g., vintage = “2018”, price around “$30”, etc) as well as embedding based retrieval. Dynamic product details such as exact prices and current availability typically aren’t indexed in embeddings. While conceptually one could search both systems separately and then merge their results, in practice, the process can be optimized to narrow down the search space.
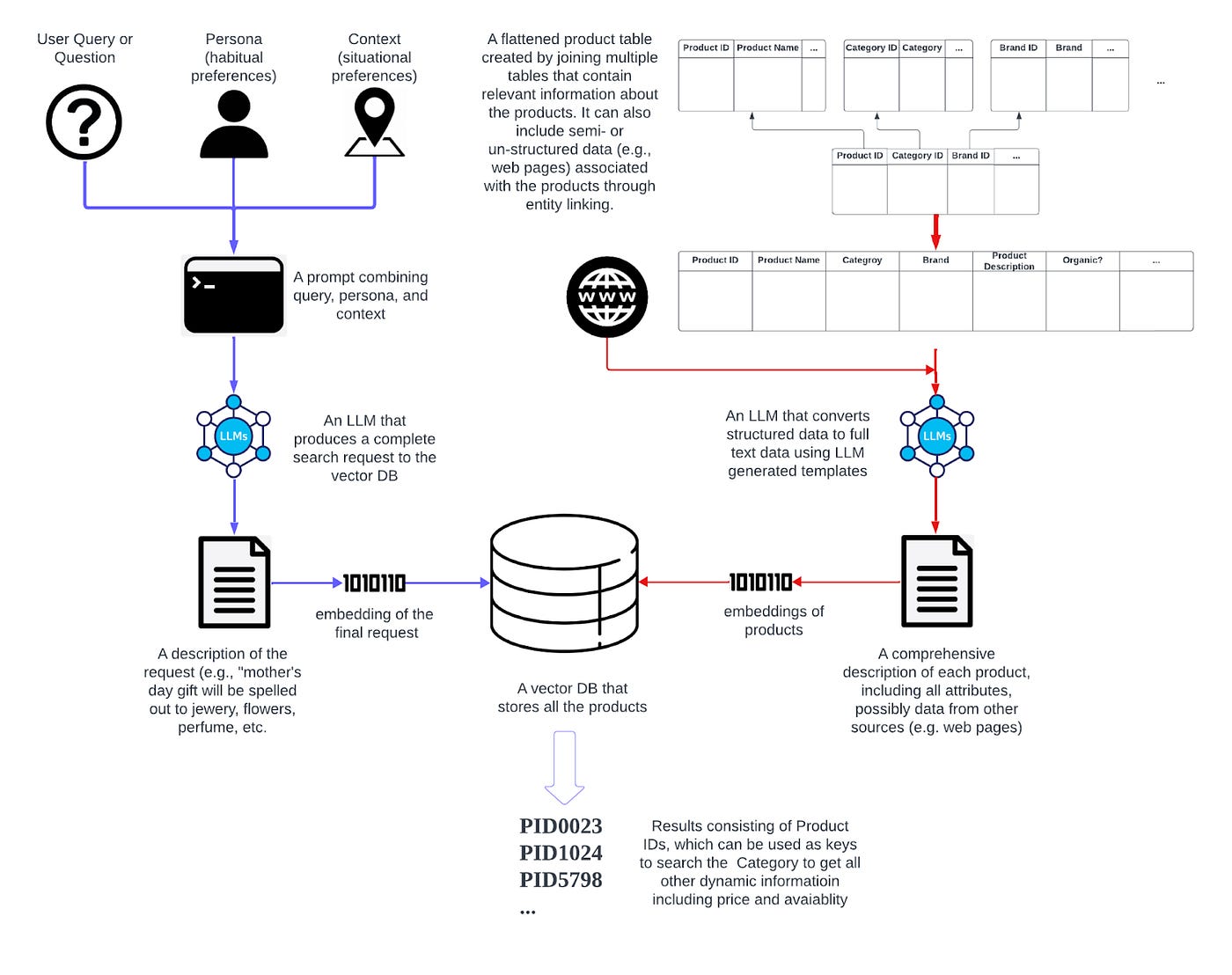
At the center of the proposed architecture lies a vector database, which uses a query embedding to locate products with similar embeddings. The query embedding, generated in real-time, incorporates three elements: the query itself, the user (habitual preferences represented by personas), and the context (situational preferences). The LLM integrates these elements into a singular request. For example, a query like “mother’s day gift” would be elaborated by the LLM into a detailed list of product categories such as “jewelry, flowers, perfume, …”. This request is then converted into an embedding.
The generation of a product embedding requires us to take more information into consideration. Most current systems use only product names to produce the embedding, which fails to fully capture the product’s characteristics. It’s more effective to compile all the available data about a product and convert this complete information into text. In the architecture presented in Fig. 22, this is achieved by joining all related tables — including product, brand, category, taxonomy, and others — into a singular, “flattened” table.

The next step involves transforming the structured data in the “flattened” table into a textual format. The text is then converted into embeddings and stored in the vector database. Fig. 23 illustrates the use of LLMs in converting structured info into textual representation. Essentially, the LLM, combining the semantics represented by the table schema with the specific data values of each product, crafts a natural language description of the product. It’s not necessary to invoke a separate call to the LLM to convert each individual product to text. In practice, we only need to call the LLM once to create a few templates. These templates, once generated, can be used to transform every product in the table into its text representation, since the products have a shared schema.
It’s important to note that much of the information about products isn’t found in the catalog but rather in other data sources, including the knowledge graphs (which can be created by LLMs) or on the web. We can simply identify the products mentioned in these sources (e.g., through entity linking), and include the information as additional representation of the product. This added information then becomes part of the text that is transformed into an embedding, as described in the earlier process. Traditionally, in e-commerce search, the focus has been on using information extraction methods to turn unstructured data (such as product description, or information about the products on the web) into structured data. However, with the emergence of LLMs, I propose we should consider a novel approach: converting all structured and semi-structured data into textual format.
The model-based architecture
The RAG-based architecture might not be the eventual solution for e-commerce search.
We envision a future where the e-commerce search system is an all-knowing system, capable of addressing every need of its customer. But the RAG-based architecture uses a generic LLM, and the information about the products resides in a vector database external to the LLM. While the LLM is able to look up the information, it does not integrate it organically with its existing knowledge to perform inference and generate insights is challenging.
An alternative approach, which could become more practical as the cost of training LLMs decreases, is to absorb this external information into the LLM through continued pre-training or other methods. The textual representations of the products I described above could be directly employed as training data for such an LLM. I will explore this approach further in the section about Enterprise LLMs.
Scalability
Foundation models, capable of handling a wide range of tasks, face deployment challenges arising from high latency and considerable computational costs. Such challenges are prominent not just in real-time applications, which require rapid responses, but also in batch processing jobs, where throughput and operational expenses are critical factors. In the following, we use two examples to illustrate the issues and explore potential strategies to alleviate these challenges.
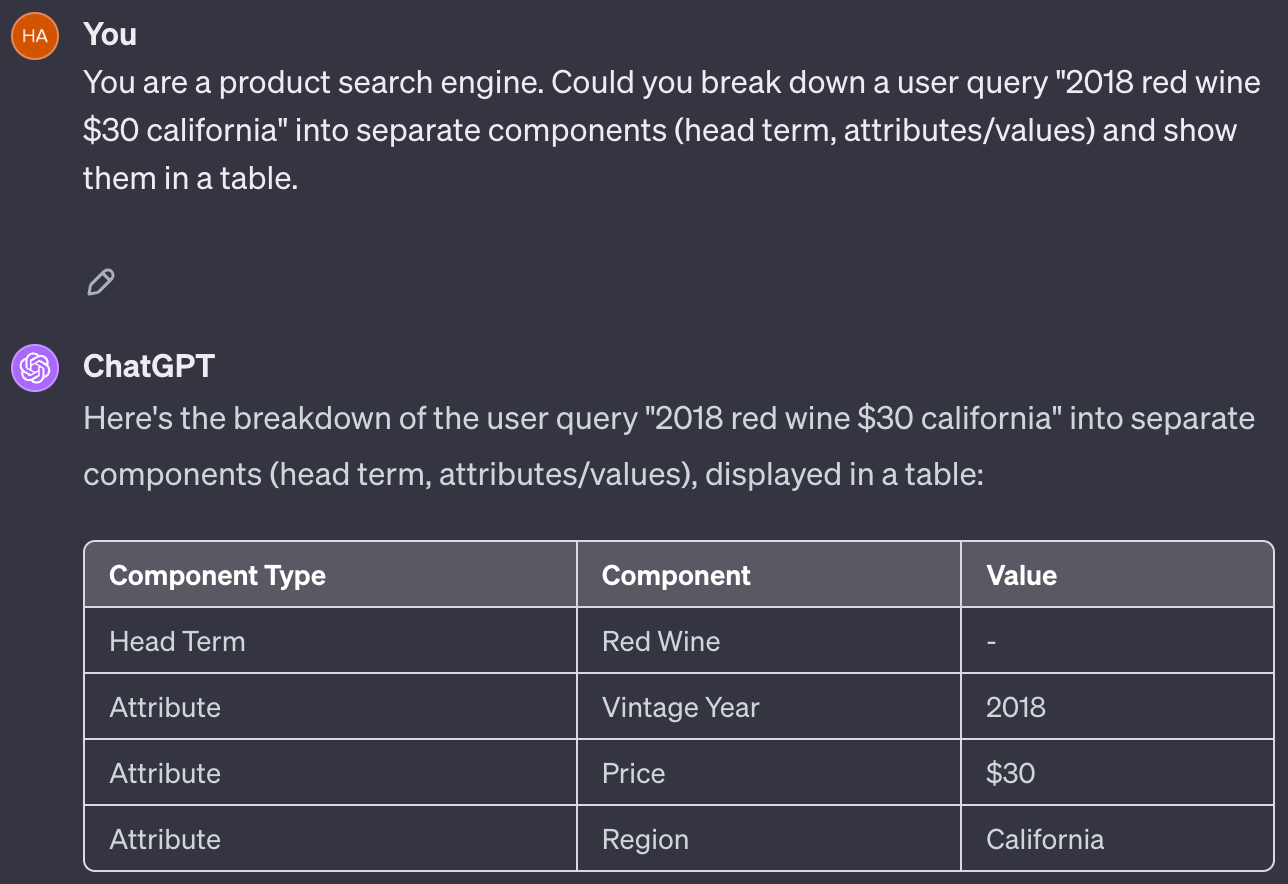
Earlier, we demonstrated that current e-commerce systems struggle with queries like “red wine $30,” because they fail to identify “red wine” as the head term and $30 as the price. Fig. 24, however, illustrates how ChatGPT adeptly manages a more complex query “2018 red wine $30 california,” showcasing LLMs’ superior query understanding capabilities.
The search stack utilizes more than a dozen machine learning models, and the development and maintenance of these models incur substantial costs. However, replacing these models with ChatGPT isn’t currently feasible. The reason is that the total latency budget for the search process, encompassing query understanding (QU), retrieval, and ranking, is approximately 2 seconds. In contrast, a singular task such as query segmentation using ChatGPT (Fig. 20) would take more than 1 second, greatly surpassing the time allocated to such a task.
As another example, consider the Persona use case we discussed in Fig. 21. This offline task involves sending users’ engagement data, like past purchases, to LLMs for summarization into explicit personas. However, the challenge arises from the fact that e-commerce platforms serve millions of customers whose engagement data is constantly updated. Repeatedly processing data for millions of customers through LLMs is impractical due to throughput and operational costs.
Moreover, the Persona task is not even the most resource-intensive. Consider our general model for utilizing LLMs in an e-commerce setting:
(query/question, user, context) => (products, explanations, presentation)
In order to reduce real-time latency, we may consider caching this mapping. It means we would need to create a 3-dimensional table, where each dimension could be enormous (even if we only consider top queries).
Clearly, the substantial computational cost and latency associated with LLMs pose a big challenge for their practical applications. To address these issues, we may explore two potential strategies.
First, considering smaller and more efficient LLMs might be beneficial. When tasks require a broad spectrum of general knowledge, such as providing suggestions for food, recipes, cuisine, and health, a larger LLM is probably necessary. However, for simpler tasks like directing a chatbot conversation to a particular function or even query segmentation, the requirements are primarily language understanding and basic reasoning, which can be handled by a smaller LLM. As smaller LLMs continue to improve in their performance, strategically assigning tasks to the most cost-efficient foundation model could offer a viable solution.
Second, implementing a smart caching mechanism could help reduce the expense associated with handling a large volume of LLM requests. In the Persona use case, for instance, the limited variety of personas suggests that users with similar behaviors are likely to share the same Persona. In particular, new interactions with the system don’t often alter a customer’s persona. With this in mind, we can analyze the data to identify similarities and eliminate redundant LLM calls for nearly identical data. This approach can be extended beyond the Persona use case to encompass all LLM interactions, whether in real-time or batch processing.
Enterprise LLMs
Many businesses have adopted pre-built LLMs like ChatGPT to upgrade their services. Yet, using these models as-is could be less than ideal for some businesses for a couple of reasons. First, these LLMs aren’t trained on specific enterprise data, which reduces their effectiveness in certain enterprise contexts. Second, these LLMs are not tailored to optimize enterprise objectives such as boosting revenue and customer satisfaction. We’ll explore these issues in more detail below.
LLMs with augmented data
It would be a significant boon for enterprises if LLMs were capable of handling questions about their specific business as effectively as they answer general world questions. E-commerce companies, for example, would find immense value in LLMs that can directly link user queries to products or ads in their catalogs. At present, this involves a two-step process. Consider a user searching for “mother’s day gift.” Initially, the e-commerce system routes this query to a standard LLM, which might suggest items like “flowers, perfume, jewelry …” Then, each of these suggestions is fed as a separate query to the company’s search engine to find specific items in the catalog. However, this method has downsides beyond just latency; it might lead to a semantic mismatch. For example, using the LLM’s generic suggestion of “perfume” without context could result in the search engine recommending a men’s fragrance like “Acqua di Gio by Giorgio Armani’’ for the “mother’s day gift” query, which isn’t contextually appropriate.
Our goal is for the LLM to seamlessly absorb catalog data from e-commerce platforms into its own knowledge. The process would involve e-commerce platforms supplying a simplified catalog dataset, ideally structured with columns such as product-id, product-name, and product-description, and supplemented by additional attributes like brand to enhance the LLM’s understanding of each product. Attributes subject to frequent changes, like price and availability, would not be included. Once the catalog data is integrated, the LLM would utilize this information to respond to queries, providing the product-ids of those products that match the query. The system could then use the product-ids as keys to access more details about the products in the catalog, and accomplish functions such as verifying price and availability, adding products to shopping carts, etc.
To develop the LLM, continuous pre-training of a foundational model is typically required. The goal of continuous pre-training is to extend the model to domains that were not part of the original training set. However, continuous pre-training could be quite costly. It’s important to note that less costly solutions such as standard fine-tuning or methods based on Retrieval-Augmented Generation (RAG) might not be adequate for our purpose. Recently, OpenAI introduced the Assistants API, which allows users to upload files (in Instacart’s case, the catalog data), and the Assistant will then answer questions using information in the uploaded files. It is not entirely clear how OpenAI incorporates the files into its internal reasoning mechanism, but iInitial tests found that this approach seems to be effective for our purpose. Yet, the latency is too big for practical production deployment. As it stands, there is no established, cost-effective solution for our objective, but ongoing developments in this area suggest potential breakthroughs could emerge soon.
LLMs with refined goals
The objective function of training a base LLM (e.g., GPT-3) is to accurately predict the next token, while the objective function of training an instruction-tuned LLM (e.g., ChatGPT) is to conduct meaningful conversations.
However, sectors like e-commerce have specific objectives beyond merely predicting the next token or facilitating meaningful conversations when it comes to training their LLMs. For an “e-commerce friendly” LLM, objectives could include:
- Maximizing Customer Engagement: The enterprise LLM should boost customer engagement, measurable by factors like: a) Time spent by customers on the platform; b) Number of products customers interact with; c) Gross Merchandise Value (GMV) generated.
- Minimizing Development Costs: While prompt engineering is crucial for proper customer interaction with a general-purpose LLM (e.g. ChatGPT) in e-commerce, it tends to be complex, unreliable, and expensive. Therefore, an optimized enterprise LLM should aim to simplify prompt engineering.
To create an “e-commerce friendly” LLM, we need to conduct instruction fine-tuning on a base LLM. This involves creating a database of (question, answer) pairs, with the answers serving as ideal examples for the LLMs to emulate in response to the questions.

To create a database of (question, answer) pairs, it’s important to first establish specific “principles” to determine what constitutes good answers. For instance, when fine-tuning an LLM for grocery/food e-commerce, one could adopt principles like:
- Expertise in Food and Grocery: Provide knowledgeable responses about food, recipes, cooking, nutrition, and health, promoting food literacy and empowering users with suitable answers, information, and products.
- Warm and Helpful Interaction: Ensure responses are friendly, useful, and informative, adopting an encouraging tone for help requests and a playful tone for lighter discussions.
- Acknowledging Limits: Humbly admit when unable to answer and strive to provide the safest, most relevant response to guide users positively.
- Engaging User Interaction: Show interest by asking follow-up questions to understand preferences and provide more relevant answers.
Additionally, after curating these principles, we can integrate them into prompts for a standard LLM (like ChatGPT) to produce answers for specific questions. Then, these generated (question, answer) pairs are used to further fine-tune the LLM. This approach, known as Reinforcement Learning from AI Feedback (RLAIF), minimizes manual labor involved in generating (question, answer) pairs and marks an advancement over the Reinforcement Learning from Human Feedback (RLHF) method, which was used to train ChatGPT. Fig. 25 shows a flowchart for creating an “e-commerce friendly” LLM through an RLAIF-like approach.








